分享内容概要
- Cassandra 是什么
- 与传统关系型数据库比较
- 与其他 NoSQL 比较
- 安装运行和基本配置
- 数据类型和存储结构
- CQL 操作语法介绍
- 编程语言对接
Cassandra 是什么
Cassandra,卡珊德拉,为希腊、罗马神话中特洛伊的公主,阿波罗的祭司。
因神蛇以舌为她洗耳,获阿波罗的赐予而有了预言能力。
又因抗拒阿波罗,预言不被人相信,成为一名不被人所听信的女先知。
特洛伊战争后被俘虏,并遭杀害。
Cassandra 数据库
Cassandra 是一套开源 分布式 NoSQL 数据库系统。
它是一种 列式存储 数据库。
最初由 Facebook 开发,2010 年时成为 Apache 顶级项目。

传统关系型数据库
传统的数据库是关系型的,且是按行来存储的
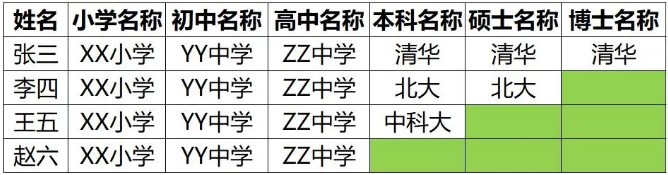
其中只有张三把一行数据填满了,李四、王五、赵六的行都没有填满
造成了一定程度的空间浪费
列式存储数据库
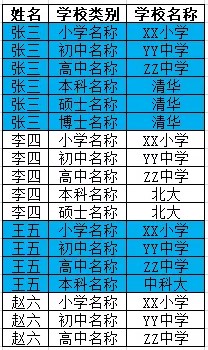
列式存储的非关系型数据库
原来张三的六列数据变成了现在的六行,所以原来的主键(即张三)重复了六次
造成了一定程度的数据冗余,但是没有空间的浪费
传统关系型数据库 VS 列式存储


世界由非结构化数据构成
我们生活在一个数据越来越丰富的世界里,但是这些数据都不能整齐的展示在一个 RDBMS 的行和列中
根据估计,世界上 90% 的数据是在过去两年中被创造 (2015),以及 80% 的商业数据是非结构化的。更重要的是,非结构化数据的增长速度是结构化数据的两倍。
Cassandra VS Redis
- Redis 注重的是高速内存缓存
- Cassandra 专注于大量数据的存储和查询
Cassandra VS MongoDB
- MongoDB 为文档型存储。无法保证数据有效性和完整性,官方建议不要使用 MongoDB 保存重要的不可丢失的信息
- Cassandra 为列式存储,通常以集群形式部署,多点备份保证数据完整性
Cassandra VS HBase
- HBase 只负责数据管理,它需要配合 HDFS 和 zookeeper 来搭建集群,主从结构,有单点失效问题的可能
- Cassandra 是一个数据存储和管理系统,p2p 架构,无单点失效问题
- 相对来说数据的写入效率 Cassandra 更高,而数据的查询效率 HBase 较好
为什么使用 Cassandra
- 拓展和复制在企业规模小的时候,不是一个大问题。而在业务和规模扩大的过程中,它很迅速地成为大问题
- Cassandra 特点是从一开始设计就解决这个问题,在集群规模管理方面非常出色
- 在机器拓展部署上,表现也特别出色,自带的备份机制,保证各个数据中心的数据安全
- 增加集群容量时,你只需启动一台新机器,并告诉 Cassandra 那里的新节点,然后,它完成其他剩下的事情
安装
# 安装 docker
wget -qO- https://get.docker.com/ | sh
# 拉取 Cassandra 镜像
docker pull cassandra:3
运行
# 启动一个节点
docker run --name cass -p 9042:9042 -e CASSANDRA_BROADCAST_ADDRESS=x.x.x.x -d cassandra:3
# 启动第二个节点
docker run --name cass2 -d -e CASSANDRA_SEEDS=x.x.x.x cassandra:3
# 数据持久化
docker run --name cass -p 9042:9042 -v /d/share/cassandra:/var/lib/cassandra -d cassandra:3
配置
配置文件位于 /etc/cassandra/cassandra.yaml,里面有非常多的可配置项,这里列出比较重要和常用的配置项:
cluster_name: 'Test Cluster'
seeds: "172.17.0.2"
broadcast_address: 172.17.0.2
native_transport_port: 9042
saved_caches_directory: /var/lib/cassandra/saved_caches
commitlog_directory: /var/lib/cassandra/commitlog
data_file_directories:
- /var/lib/cassandra/data
CQL
Cassandra 可以使用 cqlsh 进行管理, 使用的语法格式为 CQL。
docker exec -it cass cqlsh

CQL 数据表示方式
string ::= '\'' (any character where ' can appear if doubled)+ '\''
'$$' (any character other than '$$') '$$'
integer ::= re('-?[0-9]+')
float ::= re('-?[0-9]+(\.[0-9]*)?([eE][+-]?[0-9+])?') | NAN | INFINITY
boolean ::= TRUE | FALSE
uuid ::= hex{8}-hex{4}-hex{4}-hex{4}-hex{12}
hex ::= re("[0-9a-fA-F]")
blob ::= '0' ('x' | 'X') hex+
string ::= 'a''bC'
$$a'bC$$
integer ::= 2048
float ::= 256.1
boolean ::= TRUE
uuid ::= fc9a5d89-584d-4665-874e-632530525c6c
hex ::= 3f6a29
blob ::= 0x5622af8881
数据类型
| 类型 | 表示方式 |
|---|---|
| ascii | string |
| bigint | integer |
| blob | blob |
| boolean | boolean |
| counter | integer |
| date | integer, string |
| decimal | integer, float |
| 类型 | 表示方式 |
|---|---|
| double | integer float |
| duration | duration |
| float | integer, float |
| inet | string |
| int | integer |
| smallint | integer |
| text | string |
| 类型 | 表示方式 |
|---|---|
| time | integer, string |
| timestamp | integer, string |
| timeuuid | uuid |
| tinyint | integer |
| uuid | uuid |
| varchar | string |
| varint | integer |
常用类型
| 类型 | 表示方式 |
|---|---|
| text | string |
| int | integer |
| float | integer, float |
| boolean | boolean |
| date | integer, string |
| timestamp | integer, string |
自定义类型
CREATE TYPE phone (
area_code text,
number text,
)
CREATE TYPE address (
city text,
zip int,
street text,
phones map<text, phone>
)
{
"city": "Shanghai",
"zip": 201906,
"street": "No.999 Dangui Rd",
"phones": {
"mobile" : { "area_code": "021", "number": "456-1111" },
"landline" : { "area_code": "0598", "number": "456-2222" }
}
}
Keyspace
键空间(Keyspace)是用于保存列族,用户定义类型的对象,Keyspace 就像 RDBMS 中的数据库
CREATE KEYSPACE examplekey
WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};
CREATE KEYSPACE examplekey
WITH replication = {'class': 'NetworkTopologyStrategy', 'DC1': '3', 'DC2': '2'};
class复制策略,包含SimpleStrategy、NetworkTopologyStrategyreplication_factor复制因子,同一份数据复制的数量
Column Family
列族(Column Family)是多个列(Column)的集合,Column Family 就像 RDBMS 中的数据库 table,并且在 CQL 中可以用 TABLE 关键词代替 COLUMN FAMILY
CREATE COLUMN FAMILY user (
id int,
name text,
age int,
address address,
register_at time,
PRIMARY KEY (id, name)
)
- 通过
PRIMARY KEY定义主键索引,只有建立了索引的数据才能被快速高效地查询 PRIMARY KEY中的第一个字段为partition_key,之后的字段为clustering_key
PRIMARY KEY 内部储存原理
- 以上例子中的表 partition_key
id, clustering_keyname
+------+--------------+-------------------+----------------------+------------------------+
| | name = tomy: | name=tomy:age | name=tomy:address | name=tomy:register_at |
| id 1 | value = | value=6e616d6531 | value=73636f726531 | value=73636f726531 |
| | timestamp | timestamp | timestamp | timestamp |
+------+--------------+-------------------+----------------------+------------------------+
| | name = john: | name=john:age | name=john:address | name=john:register_at |
| id 2 | value = | value=6e616d6532 | value=73636f726532 | value=73636f726532 |
| | timestamp | timestamp | timestamp | timestamp |
+------+--------------+-------------------+----------------------+------------------------+
| | name = zhan: | name=zhan:age | name=zhan:address | name=zhan:register_at |
| | value = | value=6e616d6533 | value=73636f726533 | value=73636f726533 |
| | timestamp | timestamp | timestamp | timestamp |
| id 3 +--------------+-------------------+----------------------+------------------------+
| | name = lily: | name=lily:age | name=lily:address | name=lily:register_at |
| | value= | value=6e616d6534 | value=73636f726534 | value=73636f726534 |
| | timestamp | timestamp | timestamp | timestamp |
+------+--------------+-------------------+----------------------+------------------------+
Secondary Index
二级索引(Secondary Index)是用于为数据添加额外的索引
CREATE INDEX ON user(age);
CREATE INDEX index_name ON user(age);
添加了 Secondary Index 后,age 字段也可进行高效率的查询了
数据操作
- CQL 的语法和 SQL 极为相似,基本可以像操作 MySQL 一样来操作 Cassandra
SELECT name, occupation FROM users WHERE userid = 199;
SELECT COUNT (*) AS user_count FROM users;
INSERT INTO NerdMovies (movie, director, main_actor, year)
VALUES ('Serenity', 'Joss Whedon', 'Nathan Fillion', 2005);
UPDATE NerdMovies SET director='Joss Whedon', main_actor='Nathan Fillion', year=2005
WHERE movie = 'Serenity';
DELETE FROM NerdMovies WHERE movie = 'Serenity';
数据操作
- 注意 CQL 只是为了降低新手的学习成本才将语法设计的与 SQL 雷同,其背后核心的处理逻辑是完全不同的
- 所以 在掌握基本语法的基础上必须深入理解 Cassandra 的存储原理才能设计和写出高效 CQL
SELECT JSON name, occupation FROM users WHERE userid IN (199, 200, 207);
SELECT * FROM users WHERE birth_year = 1981 AND country = 'FR' ALLOW FILTERING;
INSERT INTO NerdMovies
JSON $${"movie": "Serenity", "director": "Joss Whedon", "year": 2005}$$;
USING TTL 10000
BEGIN BATCH
INSERT INTO users (userid, password, name) VALUES ('user2', 'ch@ngem3b', 'second user');
UPDATE users SET password = 'ps22dhds' WHERE userid = 'user3';
INSERT INTO users (userid, password) VALUES ('user4', 'ch@ngem3c');
DELETE name FROM users WHERE userid = 'user1';
APPLY BATCH;
对接编程语言
Cassandra 支持多种语言的客户端连接,下面以 Python 为例
pip install cassandra-driver
from cassandra.cluster import Cluster
cluster = Cluster(['106.14.160.252'], 9042)
session = cluster.connect()
session.set_keyspace('keyspace_name')
cql = "INSERT INTO users (userid, password, name) VALUES ('user2', 'ch@ngem3b', 'second user');"
session.execute(cql)